Application Note SoftMax Pro 7 ソフトウェアでの
最適なカーブフィット処理の選択
- 21種類のカーブフィット処理オプションのいずれかを使って、データを最適な方法でグラフ化する
- パラメータの独立性機能を使って、与えられたカーブフィットの適合性を調べる
- 推定相対効力と平行線分析のためのグローバルカーブフィット処理
- 同じグラフ内のプロットに独立したカーブフィット処理を適用する
PDF版(英語)
はじめに
変化率、曲線の上下漸近線、EC50/IC50値など、データの重要な特性を決定する際、正しいカーブフィット処理モデルを選択することは極めて重要である。したがって、カーブフィット処理の目標は、データに最も近いパラメータ値、言い換えれば経験的データを表す最適な数式を見つけることです。SoftMax® Pro 7ソフトウェアには、4パラメータ・ロジスティック(4P)および5パラメータ・ロジスティック(5P)非線形回帰モデルを含む、21種類のカーブフィット処理オプションが用意されています。これらは、選択されたモデルのカーブフィットパラメータを調節してデータに最適にフィットさせることにより、プロットされた曲線が濃度対反応の関係を表現する曲線にできるだけ近くなるようにします。
このテクニカルノートでは、SoftMax Pro 7で使用できるさまざまな線形回帰モデルと非線形回帰モデルについて説明します。さらに、データを最もよく表現するさまざまなカーブフィット処理を評価するために、二乗誤差の和と赤池の情報量規準法を用いたプロトコルが実装されています。
線形回帰
データを分析する最も簡単な方法は、線形回帰カーブ・フィット処理である。これは方程式y = A + Bxで表され、x(一般に濃度)は独立変数、y(応答)は従属変数です。直線の傾きはBで、Aはx=0のときのy切片です。SoftMax Proには3つの線形回帰カーブフィット処理があります。線形(y = A + Bx)、半対数(y = A + B * log10(x))、対数対数(log10(y) = A + B * log10(x))です。SoftMax Proはデータを通る最良の直線を求めます(図1)。アッセイの直線範囲は、x軸上に最低3つのデータポイントを使用して決定できますが、適合の精度を向上させるために、指定された範囲内の標準濃度を追加する必要があります1。この方法の第一の利点は単純であることである。しかし、ほとんどの場合、測定値と測定変数の関係は非線形である。
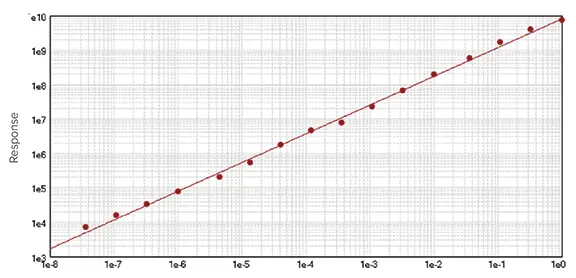
図1. 線形カーブフィット処理の例。
非線形回帰
非線形データは,一般にロジスティック回帰を用いてモデルされる.この場合,測定値と測定変数の間の関係は非線形である.目的はまた,測定値と期待値の間の偏差を最小にするそれらのパラメータ値を見つけることである.正しいフィット処理を選択するためには、モデルカーブの一般的な形状を理解し、データポイントの形状と比較することが重要です2。
SoftMax Proには、17種類の非線形回帰カーブフィット処理が用意されています。これらには、2次、3次、4次、log-logit、3次スプライン、指数、矩形双曲線(線形項あり/なし)、2パラメータ指数、2指数、2矩形双曲線、2サイト競合、ガウス、Brain-Cousens、4P、5P、5Pオルタネートがあります。SoftMax Proは、可能な限り最良のカーブフィットを実現するために、非線形カーブフィット処理で最も広く使用されている反復手順、Levenberg-Marquardtアルゴリズムを実装しています。
最も一般的な2つの非線形カーブフィットは4Pと5Pで、S字カーブを描くシグモイド関数です(図2)。4Pと5Pのカーブ・フィット処理には、それぞれ少なくとも4つのデータ点と5つのデータ点が必要であるが、これらの回帰タイプでは少なくとも6つのデータ点を使うことで、より正確なフィットが得られる1。4Pカーブ・フィット処理は、次の式で記述される:
y = ((A - D) / (1+ ((x/C)^B))) + D
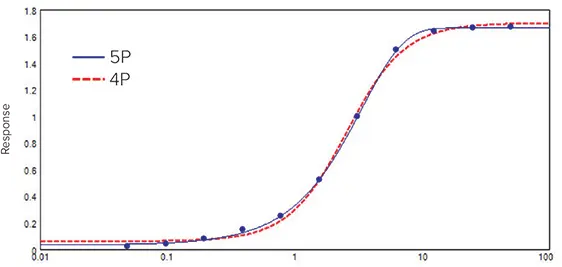
図2. 比較のために4Pと5Pのカーブフィットモデルでフィット処理した濃度反応曲線。4Pモデルは滑らかな対称曲線を与えるが、データは明らかに非対称である。したがって、5Pモデルの方がより適合度が高い。
ここで、yは応答、Dは分析物濃度無限大での応答、Aは分析物濃度ゼロでの応答、xは分析物濃度、Cは変曲点(EC50/IC50)、Bは傾き係数である。ADの場合、応答は濃度とともに増加する。4Pカーブフィット処理は対称関数であり、カーブの半分はEC50/IC50を中心にもう半分と正確に対称である。
しかし、免疫学やバイオアッセイのデータの中には対称でないものもあり、さらに柔軟性が必要なものもある。そのような状況では、5Pモデルの方がうまくいくかもしれません。5Pモデルは、もう1つのパラメータG(図2)を追加することで、非対称なデータフィッティングを可能にするからです。一般的な式は以下の通りである:
y = ((A - D) / (1 + ((x/C)^B)) G) + D
非対称パラメータは、曲線の各半分が異なることを許容する。しかし、非対称性が小さい場合は、特に平行線分析(PLA)をアッセイに使用する場合は、4Pカーブフィット処理モデルを使用することをお勧めします。
最適なカーブフィット処理の選択
正確で精密なデータを得るためには、カーブフィット、特に標準曲線の全体的な良し悪しを評価する必要がある。カーブフィットモデルを評価する際には、複数の実験を行うことが重要である。R2値は一般にフィットの良し悪しをよく表しています。R2値が0.99以上であれば、非常に良好なフィットとみなされます。しかし、R2値は、特に標準偏差がサンプル濃度によって変化する場合、誤解を招く可能性があります3。理想的には、標準偏差はすべての試料濃度で同じであるべきですが(同相統計データ)、必ずしもそうではなく、標準偏差は一般的に試料濃度とともに大きくなります(異相統計データ)。データを正規化するために開発された方法には、F統計量を用いた二乗誤差の和(SSE)法と赤池情報量規準(AIC)法がある。どちらの手法も、得られた値と予測値(選択したカーブフィット処理による)の誤差を評価するもので、非常によく似ています。
SSE法は、残差と残差プロット(残差対濃度)を用いるので、残差平方和法とも呼ばれます。残差は、各濃度における反応 y と選択したカーブフィット処理から得られる予測反応 ŷの差である4: 残差 = データ - フィット = y - ↪Ll_177. 残差はランダム誤差を表す。したがって、選択したカーブフィット処理がデータに対して正しい場合、残差は残差プロットのゼロ線の周りにランダムに散らばって見えるはずです(図3A)。残差プロット(図3B)で残差が系統的なパターンを示すなら、それはモデルがデータにうまくフィットしていないことの明らかなサインです。
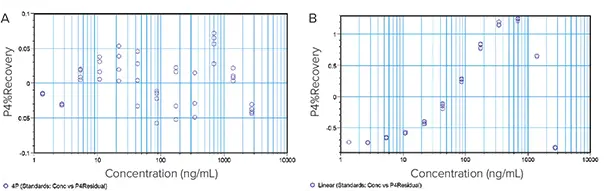
図3. 線形カーブモデルと4Pカーブモデルにフィットさせたデータの残差プロット。(A)プロットされた残差はゼロを中心にランダムに散らばっており、4Pモデルがデータをよく説明していることを示している。(B) 残差は系統的なパターンを示し、線形モデルがデータにうまく適合していないことを示している。
SSEは以下の式で求められる:
![]()
SSEを最小化することで、データ誤差が独立で正規分布しているという仮定に基づくモデル・パラメータの最尤推定値が得られる。最良のカーブフィット処理は、パラメータが最小のSSEを生成するものです。もし両方のモデルがデータに分別なくフィットするなら、最小のSSEを与えるプロットが使用すべき最良のものです。
2つのモデルが入れ子になっていて、一方が他方の特別な場合、例えば4PがG=1の5Pの特別な場合、より詳細な式(より多くのパラメータ)を持つモデルは、もう一方のモデルより小さいか等しいSSEを持つことが保証されます。これは、より多くのパラメータを持つモデルは、より多くの変曲点をデータに適合させることができるからである4。したがって、どのモデルがデータに最もフィットするかを決定するために、F検定とF確率という追加の統計計算が必要となる。F確率は、F検定とカーブフィットモデルに関連する自由度を用いて、SSEの減少が偶然に起こったかどうかを評価する。通常、0.05(信頼度95 %に相当)以下の確率がしきい値として使用され、最も詳細な式を持つモデルがデータをよりよく表現していることを意味します。
AIC法は、尤度統計量を用いて、一方が他方の特別な場合である2つのカーブフィット処理モデルについて、与えられたデータの適合度を比較する。AICは、正規分布誤差を持つデータのSSEを用いて、次のように計算できる:
AIC = n * log (SSE/n) + 2K
ここで n は標本サイズで,K は曲線を記述するパラメータの数である.標本サイズが小さい場合(すなわち,n/K < ⊖40),代わりに2次の赤池情報量規準(AICc)を使用すべきである.
AICc= AIC + 2K * (K+1) / (n-K-1)
ここで n は標本サイズで,K は曲線を記述するパラメータの数である.標本サイズが大きくなるにつれて,AICcの最後の項はゼロに近づき,AICcはAIC5と同じ結論をもたらす傾向がある.AICとAICcは、統計的な適合の良さと、この特定の適合度を達成するために推定しなければならないパラメータの数の両方を考慮に入れている。AICは、パラメータの追加にペナルティを課すので、適合は良いがパラメータ数が最小のモデルを選択する。AICまたはAICcの値が低いカーブフィット処理は、好ましいモデル、すなわち、データによくフィットする最小のパラメータを持つモデルを示す5。
どちらの方法も、どのカーブフィットがデータを最もよく記述するかを決定するのに有用であるが、帰無仮説を検定するという意味でのモデルの検定は提供しない:すなわち、フィットの良し悪しに関する情報は提供しない。つまり、適合の良し悪しに関する情報は得られないのです。もし悪いモデルだけを考慮すれば、論理的には悪いモデルの中から最良のものを選ぶことになります。カーブフィット処理は、与えられたモデルの最適なパラメータを見つけたり、2つのモデルを比較したりすることができるが、候補となるモデルは、過去の調査や科学的な考察に基づくべきである。データを説明するのに妥当なモデルの集合を特定した後、解析を行う前に、その集合の中で最も複雑なモデルとして定義されるグローバルモデルの適合性を評価すべきである。一般に、グローバルモデルが適合すれば、より単純なモデルも適合すると仮定する。
適合度の測定
SoftMax Pro 7には、データセットに対する所定のカーブフィット処理の適合性を調べるための1つの方法である「独立性」という新しいパラメータが実装されています。パラメータの依存性は、あるパラメータの最適値が他のパラメータの最適値にどの程度依存するかを示す尺度です。2つ以上のパラメータからなるカーブフィットモデルの場合、カーブを記述するパラメータは絡み合っているか(独立性が1である理想的なケース)、または冗長である(独立性が0である最悪のケース)のいずれかである。
選択したカーブフィット処理でデータをフィッティングした後、1つのパラメータを変更すると、曲線はデータ点から遠ざかります。固定されたパラメータを補正するために他のパラメータの値を変更し、曲線が点に近づいたが、最初に設定したものとは異なるカーブフィット処理になった場合、パラメータは絡み合っていることになります。一方、曲線が元の位置に戻る場合は、パラメータは冗長である。
独立性は0と1の間の数値で、1が理想的である。グラフ凡例に独立性を表示するには、カーブフィット処理のアイコンをクリックする(図4)。カーブフィット処理ウィンドウが現れる。統計タブを選び、「パラメータ依存性を計算する」にチェックを入れるだけでよい。
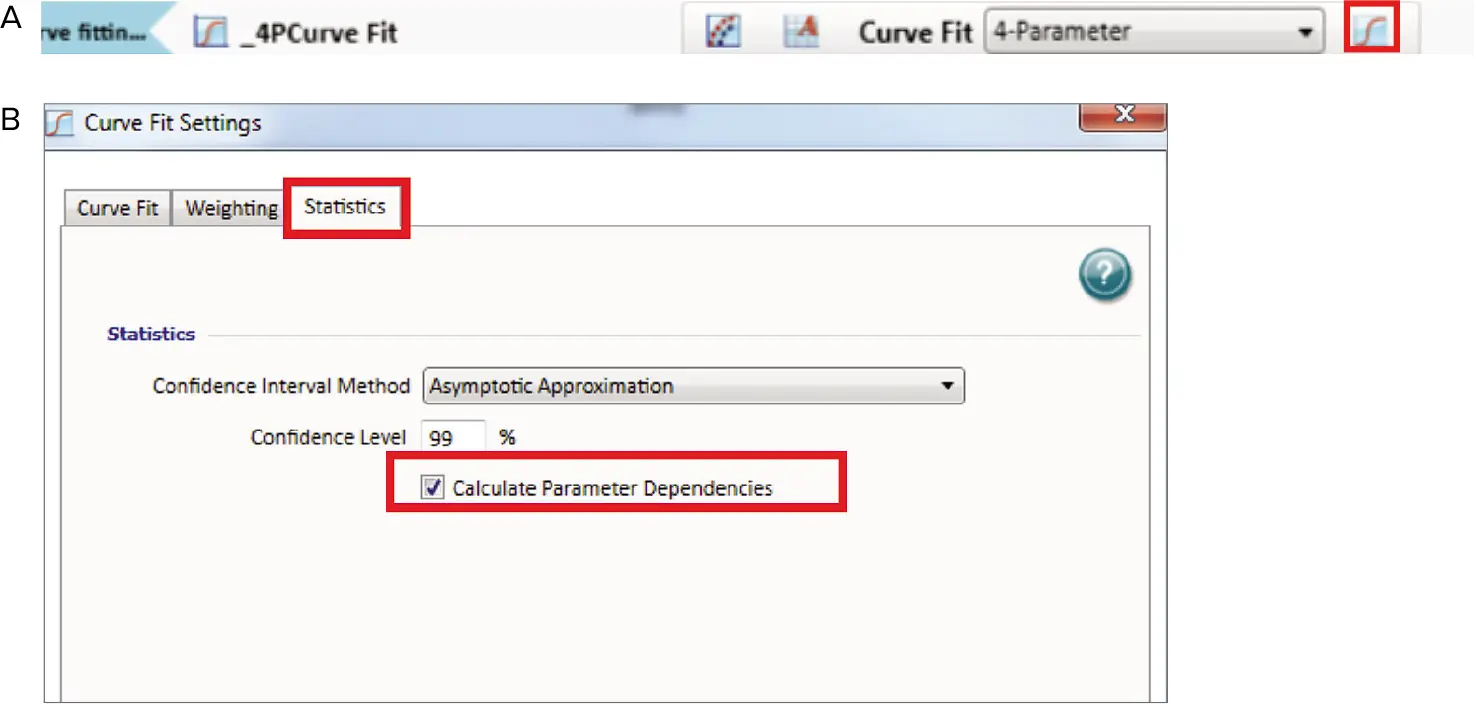
図4. (A) メニュー。(B) カーブフィット処理。
グラフの凡例に、曲線を記述する各パラメータの独立性が表示されるようになりました(図5)。
図5のグラフフィットの凡例では、パラメータの独立性が対数スケーリングのバーに変換されています。棒グラフが10本の場合は、独立性が高いことを示す。非常に小さな値だけが問題を示すので、この変換には非線形変換が使われている。1つまたは複数のパラメータに棒グラフがほとんどないか、まったくない場合は、カーブフィット処理がデータセットに合っていない可能性がある。
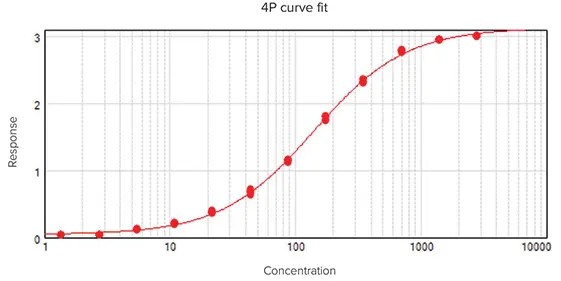

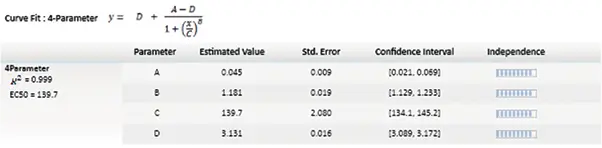
図5. パラメータの独立性を示すグラフの凡例。独立性は棒グラフに変換され、10本の棒グラフは独立性が高いことを示す。
例えば、データセットがシグモイド状で、下側と上側の漸近線がはっきりしている場合、4Pフィットが適切で、すべてのパラメータについて多くの棒グラフがある。しかし、片方または両方の漸近線が欠落している場合、AまたはDパラメータは棒グラフが少なく、データセットから信頼できる値が推測できないことを示す。
利用可能なプロトコル カーブフィット処理評価
SoftMax Proでは、データ入力時にSSE、F確率、AICc値を自動的に計算するプロトコル「カーブフィット処理評価」が開発されています。SSE法とAICc法を用いたカーブフィット処理の結論と、関連するすべての計算を封じ込めた結果セクションが実装されています(図7)。プロトコルはSoftMax Proプロトコルホームからダウンロードできます。
以下の例では、4P(図6A)と5P(図6B)のカーブフィットモデルにデータをフィット処理しました。
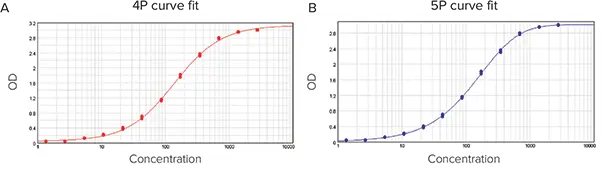
図6. カーブモデルにフィット処理したデータ。(A) 4Pカーブフィット処理。(B) 5Pカーブフィット処理。

図7. SSEとAICcテスト。カーブフィット評価プロトコルを用いて4Pおよび5Pカーブモデルにフィッティングしたデータの結果。
SSE法は、4Pと5PカーブフィットモデルのSSEがそれぞれ0.058と0.027であり、5Pカーブフィットモデルが4Pよりも良い選択であることを示した。問題は、4Pカーブフィットモデルが5Pカーブフィットモデルの特殊なケースであったことである(4PはG=1の5Pである)。したがって、5Pカーブフィットモデルは、少なくとも4Pと同程度には優れていた。追加の統計量が必要であった。F検定(61.539)とF確率(0.000)は、この例では5Pカーブフィットモデルが4Pカーブフィットモデルよりもデータをよく表現していることを確認しました。AICc法もまた、5Pが4Pカーブフィットモデルよりもデータによくフィットすることを示しました: AICcは、4Pが-405.365、5Pが-447.945であった。最後に残差プロットでは、残差がゼロラインの周りにランダムに散らばっており、どちらのカーブフィットモデルもデータに対して正しいことが確認された(図8)。これらのテスト方法を総合すると、5Pカーブフィットモデルの方がデータへの適合性が高いことが示された。
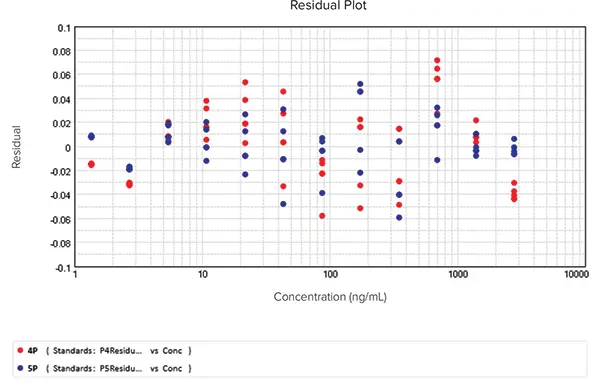
図8. 4Pおよび5Pカーブモデルにフィット処理したデータの残差プロット。
概要
SoftMax Pro 7には、広く使用されている4Pおよび5Pカーブフィットモデルを含む、幅広い数学モデルが用意されています。R2値は、データのカーブフィット処理の質を測る尺度としては不十分な場合があります。F確率を用いたSSEとAICc法は、フィットの良し悪しを比較し、確信をもって最善のカーブフィット処理モデルを選択するのに便利です。しかし、最初のステップは、どちらのモデルもデータが感覚的な値でフィットし、科学的な意味を持つことを確認することです。SoftMax Pro 7には、カーブフィット処理の良し悪しを推定するためのパラメータ依存性の計算方法が搭載されています。得られたパラメータの独立性はグラフの凡例に視覚的に表示され、データの解釈を容易にします。
参考文献
- Davis D, Zhang A, Etienne C, Huang I, and Malit M. Multiplexサンドイッチイムノアッセイにおけるカーブフィット処理の原理。Rev B Tech Note 2861。Bio-Rad Laboratories, Inc. Bio-Rad Laboratories, Inc, Hercules, CA. 2002.
- カーブフィット処理を簡単に。The Industrial Physicist. 2003; 9:24-27
- Kiser MMおよびDolan JW. 最適なカーブフィット処理の選択。LC-GC Europe. 2004年3月; 138-143
- Gottschalk PG and Dunn JR. 5パラメータ・ロジスティック: 5パラメータロジスティック:4パラメータロジスティックとの特徴づけと比較。Analytical Biochemistry. 2005: 343:54-65.
- Burnham KP and Anderson DR. Burnham KP and Anderson DR. Model Selection and Multimodel Inference: a practical information-theoretic approach. 第2版。New York: Springer-Verlag, 2002.
- Cooch EG and White GC. プログラムMARK: マークされた個体からのデータ解析、「やさしい入門」www.phidot.org/software/mark/docs/book。2001.
SoftMax Pro 7 ソフトウェアの詳細はこちら >>
PDF版(英語)