2021/3/22
AI/機械学習により高含有細胞分析の課題を克服
人工知能(AI)は、自律走行車から音声で動くパーソナル・アシスタント、さらには芸術の創造に至るまで、現代生活のさまざまな場面で活用されつつあります。しかし、AIの利点が真に際立つのは、科学とヘルスケアにおける応用です。そのひとつが、生体画像解析やハイコンテント解析(HCA)です。
HCAが成熟し、生物医学研究の定量的ツールとして広く採用されるようになるにつれ、応用領域は拡大し続け、標準的な生物学的モデルで実施される明確に定義されたアッセイの有限リストにもはや限定されなくなっています。このような複雑性の増加に対応するため、AIや機械学習によって解析手法の柔軟性と性能を向上させることに大きな焦点が当てられています。実際、多くの科学分野にわたる応用において、AIが従来の手法を凌駕している例が数多くあります。
最近まで、このような高度な機械学習手法の利用は、データサイエンスやカスタムソフトウェア開発の専門スキルを十分に利用できる研究グループに限られています。ここでは、AIを簡単に紹介し、新たに登場したターンキー機械学習ソフトウェアソリューションによって、研究者が画像内のすべてのコンテンツを活用し、より包括的な分析を実行できるようになると同時に、ユーザーの複雑な負担を軽減する方法を探ります。
AIや機械学習とは?
機械学習はAI(人工知能)の一形態です。 ディープラーニング。ニューラルネットワーク。これらはすべて、オックスフォードの辞書が定義するAIの、少し異なる用語です:
「視覚認識、音声認識、意思決定、言語間の翻訳など、通常は人間の知性を必要とするタスクを実行できるコンピューターシステムの理論と開発」。
基本的にAIとは、学習、問題解決、推論など、我々が通常人間の頭脳から連想する認知機能を模倣した、機械が示すあらゆる知性を表します。機械学習は、コンピューターがデータから素早く学習できるようにするために科学者が用いる技術です。
HCAワークフローの複雑性を克服
ハイコンテントスクリーニングまたはHCAワークフローの中核は、当社のImageXpress® Confocal HT.aiのような自動顕微鏡検査と自動画像解析に他なりません。画像取得の段階では、マイクロタイタープレート内の複数のサンプルから画像を取得します。これは、例えば、病気の表現型を救うための有効な薬剤を理解しようとする場合、膨大な量の画像データを収集することになります。
ワークフローの解析部分は、画像解析と下流解析の2つに分けられます。画像解析では、画像から特定の特徴や測定値が抽出され、統計解析が適用できる形式に変換されます。ダウンストリーム解析では、高次元のデータをすべて取り出し、科学者が解釈し、研究プロジェクトの次の段階に進むことができるように、結論を導き出すことができる形式に絞り込みます。
今日のハイコンテントスクリーニングの世界は、表現型を理解し記述することに関しては、より包括的です。単一の特徴を抽出したり、いくつかの異なる測定の比率を取る代わりに、研究者は画像内のすべてのセルについて何千もの特徴を抽出しています。これには、薬剤の標的が何であるかを知る必要も、遺伝子の機能を完全に理解する必要もないです。画像内のすべての情報豊富なコンテンツを活用することで、単に2つの異なる条件の違いを探しています。
ある種のアッセイが複雑化し、個々の細胞からより多くの情報を抽出するようになると、データはさらに圧倒的なものとなります。では、どのようにしてこれらの情報を理解し、実行可能なものにまで絞り込むのでしょうか?
従来の画像解析法は、手作業や半自動で行う場合、特に複雑で時間がかかります。困難で非常に詳細な作業のため、ヒューマンエラーやバイアスの可能性が常にあります。これにワークフローの反復性、長さ、そしてしばしば手間のかかる性質が加わると、機械学習を適用する機会が訪れます。AIは、個人差、ヒューマンエラー、バイアスを排除し、データの品質と信頼性を向上させ、ワークフローと効率を最適化します。
人間のバイアスの克服
HCAにおける機械学習の主な利点のひとつで特筆すべきは、人間のバイアスを克服する能力です。大規模なデータセットを研究するとき、人間は「不注意による無分別」と呼ばれるよく説明された現象に陥りやすいです。これは、他の注意を必要とする作業を行っているときに、予期しない観察に気づかないというものです。
例えば、以前に特定の細胞の表現型や反応を詳細に研究したことがある場合、多くの変数や測定値を封じ込めた大規模で複雑なデータセットを提示されると、同じ兆候を無意識のうちに探してしまうかもしれないです。そうすると、生物学的な関連性を持つ別の微妙な特徴や予期せぬ特徴を見落としてしまうかもしれないです。
機械学習はこの脆弱性を克服するのに役立ち、完全に偏りのない分類を行い、予期せぬ貴重な発見をもたらす可能性があります。
対物レンズのセグメンテーションへの機械学習の応用
信頼性の高い定量データは、HCAワークフローのすべての下流工程に不可欠であり、セグメンテーションはその最初の工程です。セグメンテーションとは、画像から対象オブジェクト(例:細胞小器官)を抽出し、その特徴を定量化するプロセスです。基本的には、画像のピクセルを数値データに変換する最初のステップです。
セグメンテーションは、特に1つの対物レンズに集中するように設計された従来の信号処理手法で作業する場合、困難な場合があります。細胞や組織の顕微鏡画像では、対物レンズは通常、密集しています。しかも、大きさも形も異なる。SN比が悪く、コントラストが低く、画像の解像度が低いという問題がしばしばあります。言うまでもなく、化学的擾乱やセル自体の自然な不均一性により、表現型に大きなばらつきがある場合もあります。
画像セグメンテーションの課題に対処するために、ディープラーニング・アルゴリズムをHCAワークフローの画像解析部分に適用することができます。一例として、IN Carta™画像解析ソフトウェアにはSINAPと呼ばれるディープラーニングベースのモジュールがあり、様々なデータに対応できるように設計されています。
SINAPはディープラーニングを使用しているため、調査中の試験治療から生じるサンプルの外観の大きなばらつきを考慮することができます。各治療が同等の精度でセグメンテーションされることを保証することで、このステップで抽出された情報は、その後の分析ステップで治療を比較するために確実に使用することができます。
IN Carta SINAPモジュールの使用例:
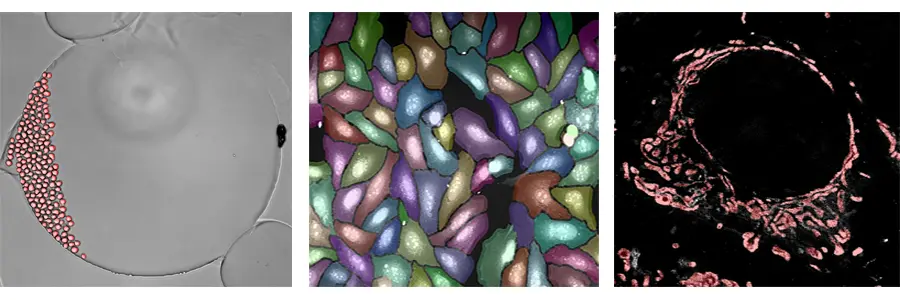
上の図は、SINAPディープラーニング・アルゴリズムを3つの全く異なるデータセットに適用した例です。左端の図は明視野分析である。この解析は、生きた細胞が分裂し動き回るのを見ながら、時間をかけて単一細胞をセグメンテーションしています。中央の図は、Cell Paintingアッセイのセグメンテーションです。細胞が密集しているにもかかわらず、SINAPは高い精度でオブジェクトをセグメンテーションしています。最後に、右端の図はミトコンドリアの超解像画像です。もう一度言いますが、この内容は全く異なっていても、同じワークフローとアルゴリズムを使って、データソースと画像内の個々のミトコンドリアを調べることができます。3つの事例すべてにおいて、SINAPディープラーニングアルゴリズムを使用することで、より正確かつ確実に、簡単にセグメンテーションを完了することができます。
対物レンズ分類への機械学習の適用
HCAワークフローでは、できるだけ多くのコンテンツを活用しようとしているため、下流の分析ステップに到達する前に、コンテンツがある程度の品質を持っていることを確認することが重要です。そこで登場するのが対物レンズ分類です。対物レンズ分類とは、表現型(細胞形態、細胞内局在、特異性マーカーの発現レベルなど)に基づいてデータセットをサブ集団に分割するプロセスです。
分類ツールを使って、関連する特徴を手作業でピッキングし、クラスを割り当てることは可能ですが、これは少数の尺度に基づく単純な表現型の変化にしか適用できません。例えば、核色素強度に基づいて細胞周期ステージを決定したり、生存率アッセイで生細胞と死細胞を分類したりするような場合です。より複雑で、より多くの特徴セットを含むものについては、対物レンズの分類にAIを使用することがより良い選択肢となります。
機械学習により、人間のユーザーは、測定値や閾値を手動で選択する必要がなくなる。代わりに、このタスクはコンピュータに割り当てられます。人間のユーザーは、異なるクラスのセルの例をコンピュータに提供します。コンピュータはそれらのクラスをどのように区別するかを見つけ出します。要するに、コンピュータは最も適切な特徴を学習し、特徴の適切な組合せを学習できるという利点があります。
IN Cartaソフトウェアには、Phenoglyphsと呼ばれる学習可能な対物レンズレベルの分類器モジュールも含まれています。Phenoglyphsモジュールは、SINAPによって抽出された情報を使用して、類似した視覚的外観を持つ対物レンズをグループ化します。そうすることで、ある治療が好ましい表現型を生み出すかどうかを評価することができ、さらに、関連する根本的なメカニズムを推測することもできます。機械学習を用いることで、すべての視覚的特徴を同時に分析し、対物レンズを正しいグループに割り当てるために必要な複雑なルールセットを最適化することができます。この高度に多変量でデータ駆動型のアプローチは、微妙な表現型の違いを解決する能力がはるかに高く、対象を誤ったグループに割り当てることに対してよりロバスト性が高いです。
IN Carta Phenoglyphsモジュールのトレーニングの4つのステップ:
- クラスタリング: このモジュールは、セグメンテーションの際に計算された指標を自動的に選択・使用し、人為的なバイアスをかけることなく、クラスタリングと呼ばれる自然なグループ分けを行います。
- ラベル: ランク付けとトレーニングのために、有効なクラス(少なくとも2つ)をすべて選択し、ラベルを付けます。
- ランク付け: このモジュールは、対物レンズをクラスに分割するために使用されるメジャーのリストをランク付けし、冗長な情報や影響の少ないメジャーを選択解除する機会を提供します。
- トレーニング: このモジュールは、オブジェクトの削除やより適切なクラスへの再割り当てなど、ユーザの入力に基づいて分類モデルを改良します。
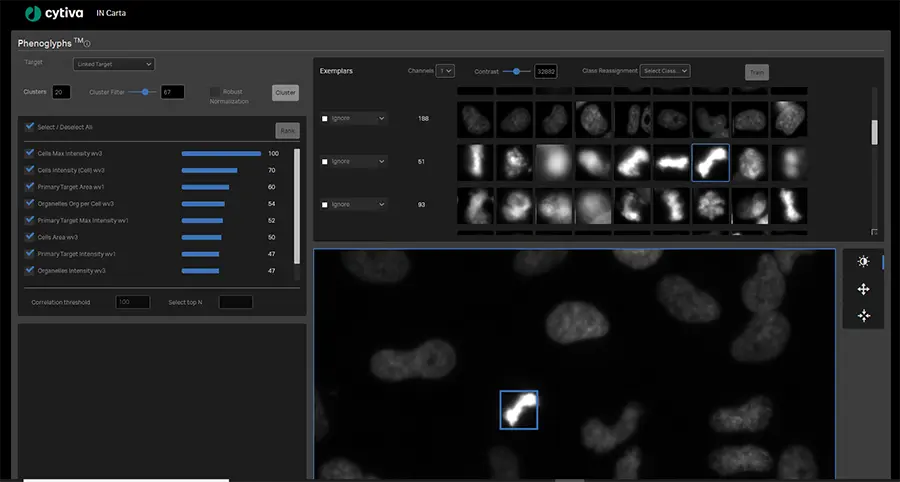
Phenoglyphs機械学習分類モジュールのトレーニング
ユーザーとしては、Phenoglyphsモジュールがデータセット全体にモデルを適用する前に、各クラスの少数の例について確認し、入力を行うだけでよいです。このアプローチにより、クラス割り当ての最初のステップでのユーザー入力の必要性が最小限になり、大幅な時間の節約になります。
当て推量を排除
IN Cartaソフトウェア独自の特徴は、SINAPとPhenoglyphsモジュールの両方に組み込まれている教師なし学習ステップです。教師なし学習ステップは初期結果を生成し、ユーザーがアルゴリズムの決定を確認または修正するだけで繰り返し最適化されます。これにより、解析のための実行可能な出発点を決定する負担がなくなり、退屈な試行錯誤でパラメーターを微調整する必要がなくなります。SINAPとPhenoglyphsを組み合わせることで、ユーザーエクスペリエンスはエンドツーエンドのワークフローとなり、画像解析や統計解析の経験が不要となり、結果までの時間が短縮されます。
機械学習によるHCAワークフローの最適化についての詳細はこちらをご覧ください。IN Cartaソフトウェアのページをご覧ください。